Cơ sở dữ liệu mờ và Truy vấn mềm dẻo (Fuzzy data bases) ver.2
1. Giới thiệu và Đặt vấn đề
1.1 Bản chất của các hệ thống phân đôi (Dichotomous Systems)
Trong kỷ nguyên số, thế giới của cơ sở dữ liệu (CSDL) về cơ bản là thế giới của máy tính kỹ thuật số, một trong những đại diện tiêu biểu nhất của các "hệ thống phân đôi" (dichotomous systems). Kiến trúc phần cứng và logic nền tảng của các hệ thống này được xây dựng trên nguyên lý nhị phân: bóng bán dẫn bật hoặc tắt, trạng thái là 0 hoặc 1, mệnh đề là đúng (True) hoặc sai (False).
Hệ quả tất yếu của kiến trúc này là phương thức lưu trữ dữ liệu mang tính chất "rõ" (crisp). Mọi quy trình xử lý dữ liệu—từ khâu nhập liệu (input), lưu trữ (storage) đến truy vấn (querying)—đều bị ép buộc vào các khuôn mẫu chính xác tuyệt đối, bất chấp việc các mối quan hệ thực tế được mô tả trong cơ sở dữ liệu có thể chứa đựng sự không chắc chắn, mơ hồ hay mờ nhạt.
Các cơ sở dữ liệu hiện đại không chỉ chứa các giao dịch tài chính chính xác mà còn chứa các mô tả về hệ thống kỹ thuật, hoạt động của doanh nghiệp, các hoạt động khoa học, hay các đặc điểm địa lý (GIS). Trong các miền ứng dụng này, ranh giới giữa "tốt" và "xấu", "cao" và "thấp", hay "đáng tin cậy" và "không đáng tin cậy" hiếm khi là một đường ranh giới sắc nét. Tuy nhiên, các hệ thống CSDL truyền thống buộc người dùng phải định nghĩa các ngưỡng cứng nhắc (ví dụ: nhiệt độ > 30 độ là nóng, <= 30 độ là không nóng), dẫn đến việc mất mát thông tin ngữ nghĩa quan trọng.
1.2 Sự trỗi dậy của lý thuyết Tập mờ trong Khoa học Máy tính
- Để giải quyết mâu thuẫn giữa tính cứng nhắc của máy tính và tính mềm dẻo của thực tế, các nhà nghiên cứu trên khắp thế giới đã dành khoảng 20 năm (tính đến thời điểm tài liệu gốc của Zimmermann được xuất bản) để nghiên cứu việc ứng dụng Lý thuyết Tập mờ (Fuzzy Set Theory) vào cơ sở dữ liệu.
- Lý thuyết tập mờ, được khởi xướng bởi Lotfi Zadeh, cung cấp một khung toán học để mô hình hóa sự không chính xác (imprecision).
- Thay vì một phần tử thuộc về hoặc không thuộc về một tập hợp (hàm đặc trưng ), lý thuyết tập mờ cho phép một phần tử thuộc về tập hợp với một mức độ nhất định trong khoảng .
- Được biểu diễn qua hàm thuộc (membership function):
- Điều này phản ánh chính xác hơn cách con người nhận thức và phân loại thế giới.
- Thay vì một phần tử thuộc về hoặc không thuộc về một tập hợp (hàm đặc trưng ), lý thuyết tập mờ cho phép một phần tử thuộc về tập hợp với một mức độ nhất định trong khoảng .
1.3 Khái quát lý thuyết tập mờ
- Tập mờ: Không giống tập cổ điển (crisp set) với thành viên 0/1, tập mờ gán độ thuộc (membership degree) từ [0,1] cho mỗi phần tử.
- Biến ngôn ngữ (linguistic variables): Biến có giá trị là từ ngữ (terms) như "cao", "trung bình", "thấp", được định nghĩa bằng hàm thuộc mờ (membership functions). Ví dụ: Biến "chất lượng" với terms "high", "medium".
- Quan hệ mờ (fuzzy relations): Mở rộng quan hệ cổ điển bằng cách thêm độ thuộc cho mỗi tuple (xem Chương 6 trong tài liệu tham khảo).
- Tổng hợp mờ (aggregation): Sử dụng t-norm (cho "and" nghiêm ngặt), t-conorm (cho "or"), hoặc toán tử bù (compensatory operators) như γ-operator để kết hợp độ thuộc.
1.4 Khoảng cách giữa lý thuyết và công nghệ CSDL thương mại
- Mặc dù nền tảng lý thuyết đã khá vững chắc, việc hiện thực hóa công nghệ "ngân hàng dữ liệu mờ" (fuzzy databank technology) trong thương mại vẫn tụt hậu so với lý thuyết.
- Nguyên nhân chính của sự chậm trễ này nằm ở sự phát triển quá nhanh của chính công nghệ cơ sở dữ liệu.
- Lịch sử phát triển CSDL đã trải qua các bước chuyển mình mạnh mẽ: từ mô hình lý thuyết đồ thị (graph-theoretic paradigm), chuyển sang ngân hàng dữ liệu quan hệ (relational databanks), và tiếp đó là các thiết kế hướng đối tượng (object-oriented designs). Mỗi khi một mô hình dữ liệu mới (paradigm) xuất hiện và trở thành tiêu chuẩn, các phương pháp tiếp cận mờ lại phải được tái cấu trúc để phù hợp với mô hình đó. Sự "đuổi bắt" này khiến cho các hệ quản trị cơ sở dữ liệu (DBMS) thương mại lớn (như Oracle, SQL Server) ngần ngại trong việc tích hợp sâu các kiểu dữ liệu mờ vào lõi hệ thống của họ, buộc các giải pháp mờ thường tồn tại dưới dạng các lớp ứng dụng bên trên.
- Trong hướng dẫn này, chúng ta sẽ tập trung vào hai hướng tiếp cận chính mà Zimmermann và các cộng sự đã hệ thống hóa:
- Mô hình CSDL Quan hệ Mờ
- Mô hình Truy vấn Mờ dựa trên sự tương đồng.
2. Cơ sở lý thuyết về mô hình quan hệ
Để hiểu sâu sắc về CSDL mờ, trước hết chúng ta phải nắm vững cấu trúc mà nó cố gắng mở rộng: Mô hình Quan hệ (Relational Data Model).
2.1 Cấu trúc của mô hình quan hệ (Relational Model)
Mô hình quan hệ dựa trên các khái niệm của lý thuyết tập hợp cổ điển (set-theoretic concepts). Về cơ bản, các cơ sở dữ liệu quan hệ bao gồm các quan hệ (relations) được thể hiện dưới dạng bảng hai chiều (hàng và cột).
- Bộ (Tuples): Các hàng trong bảng, tương ứng với các bản ghi (records) dữ liệu. Mỗi bộ đại diện cho một thực thể hoặc một mối quan hệ thực tế.
- Miền giá trị hoặc Thuộc tính (Domains or Attributes): Các cột trong bảng, tương ứng với các trường (fields) thông tin. Mỗi thuộc tính có một miền giá trị xác định (ví dụ: số nguyên, chuỗi ký tự).
- Khóa (Keys): Một hoặc nhiều thuộc tính được chọn để định danh duy nhất cho mỗi bộ trong quan hệ.
2.2 Chuẩn hóa dữ liệu và tính cứng nhắc của dạng chuẩn 3 (3NF)
Trong thiết kế CSDL chuyên nghiệp, các quan hệ thường được chuẩn hóa để tránh dư thừa và mâu thuẫn dữ liệu. Zimmermann nhấn mạnh việc xem xét các quan hệ ở Dạng chuẩn 3 (Third Normal Form - 3NF).
Một quan hệ đạt 3NF phải thỏa mãn hai đặc điểm cốt lõi:
- Phụ thuộc đầy đủ vào khóa: Mỗi thuộc tính không khóa phải phụ thuộc hoàn toàn vào toàn bộ khóa chính (chứ không phải một phần của khóa).
- Không phụ thuộc bắc cầu: Các thuộc tính không khóa phải phụ thuộc trực tiếp vào khóa chính, không phụ thuộc vào nhau (non-transitively dependent).
Sự chặt chẽ toán học này tạo ra hiệu quả cao trong lưu trữ và truy xuất nhưng đồng thời tạo ra một "bức tường thép" ngăn cản sự biểu diễn các thông tin mơ hồ. Trong mô hình chuẩn này, giá trị của thuộc tính phải là nguyên tử (atomic) và chính xác. Chúng ta không thể lưu trữ "khoảng 5 đến 10" hay "khá cao" trong một trường số nguyên (integer) được định nghĩa chặt chẽ mà không phá vỡ các quy tắc ràng buộc toàn vẹn của CSDL.
2.3 Vấn đề biểu diễn ngữ nghĩa trong CSDL truyền thống
Hãy xem xét Ví dụ 12-1 được đề cập trong tài liệu. Một cơ sở dữ liệu mô tả các vật liệu được cung cấp bởi các nhà cung cấp khác nhau.
Bảng: Suppliers (Nhà cung cấp)
| supplier (nhà cung cấp) | location (địa điểm) | material (vật liệu) | quality (chất lượng) |
|---|---|---|---|
| DEWAG | Paris | 802.025 | medium |
| DEWAG | Paris | 802.020 | medium |
| MAM | Berlin | 802.025 | high |
| KBA | Hamburg | 802.025 | high |
| INFORM | Aachen | 802.025 | low |
- Trong bảng trên, thuộc tính quality chứa các giá trị như "medium", "high", "low".
- Trong một CSDL rõ (crisp database), đây chỉ là các chuỗi ký tự (strings). Máy tính không hiểu "high" tốt hơn "low".
- Một truy vấn WHERE quality = 'high' sẽ trả về kết quả chính xác, nhưng WHERE quality = 'very high' sẽ không trả về gì cả, và WHERE quality > 'medium' là vô nghĩa về mặt ngữ nghĩa (trừ khi so sánh theo thứ tự bảng chữ cái).
Vấn đề cốt lõi ở đây là: Tính ngữ nghĩa của dữ liệu bị tách rời khỏi biểu diễn lưu trữ. Các hệ thống rõ lưu trữ các ký hiệu (symbols) thay vì ý nghĩa (meanings).
3. Cấu trúc cơ sở dữ liệu quan hệ mờ
Để khắc phục các hạn chế trên, CSDL quan hệ mờ mở rộng mô hình quan hệ theo hai hướng chính: Mờ hóa thuộc tính và Mờ hóa quan hệ.
3.1 Mở rộng mô hình quan hệ: Từ giá trị rõ đến biến ngôn ngữ
Sự mờ hóa của một quan hệ có thể được mô hình hóa bằng cách coi các giá trị ngôn ngữ của các miền thuộc tính là các thuật ngữ (terms) của biến ngôn ngữ (linguistic variables).
Trong lý thuyết tập mờ, một biến ngôn ngữ (ví dụ: "Chất lượng") nhận giá trị là các từ ngữ (ví dụ: "cao", "thấp", "trung bình") thay vì các con số. Mỗi từ ngữ này lại được định nghĩa bởi một tập mờ trên miền nền (ví dụ: thang điểm từ 0 đến 100).
Khi đó, bảng dữ liệu không còn chứa các chuỗi vô tri nữa, mà chứa các nhãn của các tập mờ. Hệ thống CSDL mờ sẽ hiểu rằng "high" tương ứng với một phân bố điểm số nhất định và có mối quan hệ chồng lấn với "medium".
3.2 Độ thuộc của Bộ (Tuple Membership Degree - )
Một cách tiếp cận sâu sắc hơn là gán cho mỗi bộ (tuple) trong quan hệ một độ thuộc bổ sung (). Giá trị này biểu thị mức độ mà mối quan hệ được mô tả trong dòng đó là đúng thực tế.
Xét bảng "Reliability" (Độ tin cậy) được mở rộng trong tài liệu nghiên cứu:
Bảng: Reliability (Mờ hóa)
| supplier (nhà cung cấp) | material (vật liệu) | reliability (độ tin cậy) | (hệ số độ tin cậy) |
|---|---|---|---|
| DEWAG | 802.025 | high | 0.8 |
| DEWAG | 802.020 | medium | 0.7 |
| MAM | 802.025 | medium | 0.6 |
| KBA | 802.025 | low | 0.8 |
| INFORM | 802.025 | high | 0.9 |
3.3 Phân tích ví dụ: Bảng "Reliability - Độ tin cậy" và ý nghĩa thực tiễn
Trong bảng trên, chúng ta thấy sự kết hợp giữa dữ liệu rõ và siêu dữ liệu mờ:
- Các giá trị thuộc tính reliability (high, medium, low) vẫn được định nghĩa rõ (như các biểu tượng).
- Giá trị chỉ ra mức độ tin cậy của thông tin đó hoặc mức độ liên kết giữa nhà cung cấp và độ tin cậy được gán.
Phân tích sâu:
- Dòng cuối cùng:
INFORM | 802.025 | high | 0.9Điều này có nghĩa là hệ thống có độ chắc chắn 90% (hoặc mức độ sự thật là 0.9) rằng nhà cung cấp INFORM cung cấp vật liệu 802.025 với độ tin cậy cao. - Dòng thứ ba:
MAM | 802.025 | medium | 0.6Mức độ chắc chắn 60% về việc MAM có độ tin cậy trung bình.
Mô hình này cho phép lưu trữ các thông tin không hoàn hảo từ thế giới thực (ví dụ: thông tin thu thập từ khảo sát khách hàng, nơi ý kiến không thống nhất). Tuy nhiên, tài liệu cũng chỉ ra rằng: "Các cơ sở dữ liệu mờ vẫn còn rất hiếm trong thực tế". Các công ty ngần ngại thay thế các ngân hàng dữ liệu (rõ) của họ bằng các ngân hàng dữ liệu mờ trước khi họ thực sự bị thuyết phục về tính cần thiết.
Do đó, hướng ứng dụng thứ hai—Truy vấn Mờ trên CSDL Rõ—trở nên khả thi và quan trọng hơn trong bối cảnh hiện tại.
4. Phương pháp truy vấn mềm dẻo
Cách tiếp cận này không yêu cầu thay đổi cấu trúc lưu trữ dữ liệu (vẫn dùng SQL Server, Oracle, MySQL truyền thống). Thay vào đó, sự "mờ hóa" diễn ra ở tầng giao diện truy vấn. Đây là giải pháp tận dụng sức mạnh của lý thuyết tập mờ để thiết kế các ngôn ngữ truy vấn mờ (fuzzy query languages) mà không cần thay thế hệ thống cũ.
4.1 Nguyên lý giảm độ phức tạp và trích xuất sự phù hợp
Đối với cơ sở dữ liệu, các tập mờ có thể được sử dụng theo hai hướng chính:
- Phân biệt mức độ: Phân biệt các mức độ liên quan, độ mạnh của quan hệ (như đã thấy ở phần ).
- Giảm độ phức tạp: Trích xuất thông tin phù hợp từ khối lượng dữ liệu khổng lồ.
Hướng thứ hai tập trung vào quan điểm của người dùng. Từ góc độ người dùng, không phải tất cả các giá trị trong miền của một thuộc tính đều cần được xem xét là khác nhau.
- Ví dụ, đối với một nhà quản lý mua hàng, mức giá 100 USD và 101 USD có thể được coi là "như nhau" hoặc "bàng quan" (indifferent) trong bối cảnh ra quyết định chiến lược.
4.2 Lớp tương đương (Equivalence Classes) và ngữ cảnh (Context)
Để hình thức hóa sự "bàng quan" này, chúng ta sử dụng khái niệm Lớp tương đương (Equivalence Classes). Chúng ta gọi các phần tử trong miền của một thuộc tính có cùng ý nghĩa trong một ngữ cảnh nhất định là "tương đương".
Quan hệ tương đương này phân hoạch miền giá trị thành các tập con rời nhau. Việc đưa vào các lớp tương đương giúp giảm độ phức tạp của dữ liệu cần xem xét, chuyển từ không gian giá trị liên tục hoặc rời rạc lớn sang một số ít các lớp khái niệm.
4.3 Phân hoạch miền giá trị: Từ tập rõ đến các vùng ngữ nghĩa
Xét ví dụ 12-2 trong tài liệu:
Miền của thuộc tính "quality" được xác định là:
Trong một truy vấn cụ thể, người dùng chỉ quan tâm liệu chất lượng là "tốt" (gồm high hoặc medium) hay "xấu" (gồm sufficient hoặc low). Điều này có thể được biểu diễn bằng một quan hệ tương đương :
| E (mức đánh giá) | high (cao) | medium (trung bình) | sufficient (đủ) | low (thấp) |
|---|---|---|---|---|
| high | 1 | 1 | 0 | 0 |
| medium | 1 | 1 | 0 | 0 |
| sufficient | 0 | 0 | 1 | 1 |
| low | 0 | 0 | 1 | 1 |
Hệ quả là miền thuộc tính "quality" trong ngữ cảnh C này được phân hoạch thành:
Vấn đề phát sinh (The Crisp Boundary Problem):
Mặc dù việc phân hoạch này giúp đơn giản hóa việc ra quyết định (chỉ còn 2 nhóm: Tốt và Xấu), nhưng nó lại tạo ra một vấn đề mới của hệ thống rõ:
- Sự thay đổi đột ngột. Một nhà cung cấp có chất lượng "medium" được xếp vào nhóm "Tốt", nhưng nếu chất lượng giảm nhẹ xuống "sufficient", họ lập tức rơi vào nhóm "Xấu".
- Trong thực tế quản trị, sự chuyển đổi này nên là một quá trình dần dần.
Để giải quyết vấn đề này, chúng ta cần chuyển từ các lớp tương đương rõ sang các Tập mờ (Fuzzy Sets) và sử dụng các toán tử tổng hợp tinh vi hơn, đặc biệt là toán tử Gamma.
5. Toán tử tổng hợp Gamma
Khi thực hiện truy vấn đa tiêu chí (ví dụ: Tìm nhà cung cấp có "Chất lượng tốt" VÀ "Giao hàng nhanh"), chúng ta cần kết hợp (aggregate) các giá trị độ thuộc của từng tiêu chí. Việc lựa chọn toán tử tổng hợp quyết định tính "mềm dẻo" và "nhân bản" của hệ thống.
5.1 Hạn chế của các toán tử kinh điển (Min/Max) trong ra quyết định
Trong logic mờ kinh điển (Zadeh), phép giao (AND) thường được thực hiện bằng toán tử Min, và phép hợp (OR) bằng toán tử Max.
-
Toán tử Min (Non-compensatory):
Đây là toán tử không bù trừ. Nếu một ứng viên có Chất lượng tuyệt vời (0.9) nhưng Giao hàng hơi chậm một chút (0.1), điểm tổng hợp sẽ là 0.1. Điểm mạnh không thể bù đắp cho điểm yếu. Điều này quá khắt khe trong nhiều tình huống thực tế.
-
Toán tử Max (Fully compensatory):
Đây là toán tử bù trừ hoàn toàn. Chỉ cần một tiêu chí tốt là đủ. Điều này lại quá lỏng lẻo cho các yêu cầu cần sự cân bằng.
5.2 Khái niệm "Bù trừ" (Compensation) trong tâm lý học nhận thức
- Các nghiên cứu thực nghiệm của Zimmermann và Zysno (1980) đã chỉ ra rằng con người hiếm khi sử dụng toán tử AND (Min) hoặc OR (Max) thuần túy khi ra quyết định. Thay vào đó, họ sử dụng một cơ chế "bù trừ" (averaging/compensation).
- Một quyết định thực tế thường nằm giữa "AND logic" và "OR ngôn ngữ". Chúng ta cần một toán tử có thể điều chỉnh mức độ bù trừ này, cho phép một thuộc tính yếu được cứu vãn phần nào bởi một thuộc tính mạnh, nhưng không hoàn toàn bị lấn át.
5.3 Định nghĩa và cơ chế hoạt động của toán tử Gamma
Để mô hình hóa hành vi này, Zimmermann đề xuất Toán tử Gamma (còn gọi là "Compensatory AND"). Đây là sự kết hợp của Tích đại số (Algebraic Product - đại diện cho AND) và Tổng đại số (Algebraic Sum - đại diện cho OR).
Công thức toán học của toán tử Gamma cho việc tổng hợp m tập mờ là:
Trong đó:
- : Là Tích mờ (Fuzzy Product). Nó có xu hướng làm giảm giá trị kết quả (decreasive), nhỏ hơn hoặc bằng giá trị nhỏ nhất. Đây là thành phần "nghiêm khắc" (AND).
- : Là Tổng mờ (Fuzzy Sum). Nó có xu hướng làm tăng giá trị kết quả (increasive), lớn hơn hoặc bằng giá trị lớn nhất. Đây là thành phần "khoan dung" (OR).
- : Tham số điều chỉnh mức độ bù trừ.
5.4 Tại sao ? Sự cân bằng giữa VÀ và HOẶC
Việc lựa chọn tham số là cốt yếu:
- Nếu : Công thức trở thành Tích đại số thuần túy (tương tự AND). Không có bù trừ.
- Nếu : Công thức trở thành Tổng đại số thuần túy (tương tự OR). Bù trừ hoàn toàn.
- Nếu : Toán tử lấy trung bình nhân (geometric mean) của thành phần AND và thành phần OR.
Trong Ví dụ 12-3 của tài liệu, tác giả chọn với lý do: "Mô hình hóa một sự tổng hợp nằm chính giữa 'logical AND' và 'linguistic OR'". Điều này phản ánh tư duy quản trị: chúng ta muốn nhà cung cấp vừa có chất lượng tốt vừa giao hàng nhanh (AND), nhưng chúng ta cũng sẵn sàng chấp nhận sự đánh đổi nhẹ giữa hai yếu tố này (Compensatory).
6. Phân tích tình huống ứng dụng
Phần này sẽ hướng dẫn chi tiết từng bước (step-by-step tutorial) việc áp dụng lý thuyết trên vào một bài toán quản trị cụ thể, dựa trên dữ liệu từ Example 12-3
6.1 Thiết lập bài toán và dữ liệu ban đầu
Bối cảnh: Một nhà quản lý bộ phận thu mua muốn đánh giá các nhà cung cấp để đưa ra các hành động cải thiện tình hình cung ứng.
Dữ liệu thô (Raw Data Base):
| mã (ID) | nhà cung cấp (supplier) | vật liệu (material) | chất lượng (quality) | độ trễ (delay - days) |
|---|---|---|---|---|
| 1 | BAW | 802.025 | sufficient | 8 |
| 2 | DEWAG | 802.025 | medium | 5 |
| 3 | DEWAG | 809.200 | high | 8 |
| 4 | KBA | 802.025 | sufficient | 7 |
| 5 | KBA | 809.200 | sufficient | 3 |
| 6 | KBA | 840.024 | low | 9 |
| 7 | MD | 802.025 | sufficient | 8 |
| 8 | MD | 809.200 | medium | 4 |
| 9 | MTX | 802.025 | high | 2 |
| 10 | MTX | 840.024 | high | 4 |
| 11 | MAM | 802.025 | low | 7 |
| 12 | MAM | 840.024 | medium | 6 |
| 13 | ZT | 809.200 | high | 8 |
| 14 | ZT | 840.024 | medium | 2 |
Miền giá trị:
- (ngày)
6.2 Giai đoạn 1: Phân loại dựa trên ngữ cảnh rõ và nhược điểm
Ban đầu, nhà quản lý định nghĩa các lớp ngữ cảnh rõ (Crisp Contexts):
- Chất lượng:
- Tốt (Good):
- Xấu (Bad):
Người quản lý bộ phận mua hàng tin rằng đối với truy vấn, các ngữ cảnh sau đây là phù hợp:
- Độ trễ:
- Chấp nhận được (Acceptable): [1, 5]
- Không chấp nhận được (Unacceptable): (5, 10]
Dựa trên hai trục này, ma trận quyết định 2 x 2 được hình thành:
| Chấp nhận được (Delay ≤ 5) | Không chấp nhận được (Delay > 5) | |
|---|---|---|
| Chất lượng Tốt | Lớp C1: Mở rộng quan hệ (Expand relationship) | Lớp C2: Yêu cầu giảm độ trễ (Improve delay) |
| Chất lượng Xấu | Lớp C3: Yêu cầu cải thiện chất lượng (Improve quality) | Lớp C4: Chấm dứt quan hệ (Terminate) |
Kết quả phân loại rõ:
- MTX: Cung cấp vật liệu với độ trễ 2 và 4 (đều <= 5) và chất lượng High (Tốt). => Thuộc hoàn toàn Lớp C1.
- BAW: Độ trễ 8 (> 5) và chất lượng Sufficient (Xấu). => Thuộc hoàn toàn Lớp C4.
Nhược điểm: Sự phân loại này quá cứng nhắc. Một nhà cung cấp có độ trễ 6 ngày (C2 - bị khiển trách) hầu như không khác biệt với 5 ngày (C1 - được khen thưởng). Sự thiếu vắng "vùng xám" có thể gây ức chế cho nhà cung cấp và dẫn đến các quyết định quản trị sai lầm.
6.3 Giai đoạn 2: Mờ hóa các thuộc tính chất lượng và thời gian trễ
Để khắc phục, ta định nghĩa lại các thuộc tính dưới dạng Biến ngôn ngữ Mờ.
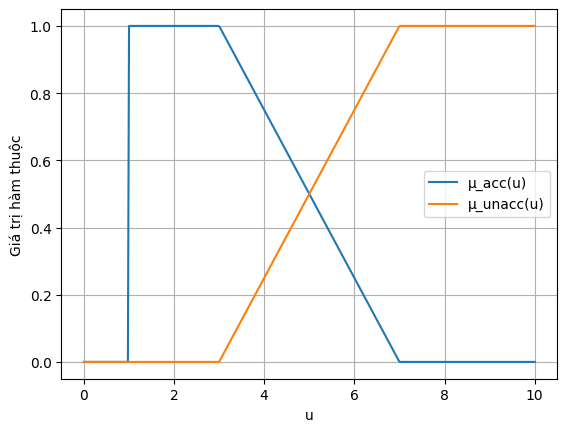
A. Biến ngôn ngữ "Delay" (Độ trễ)
Ta định nghĩa hai thuật ngữ mờ: "Acceptable" (Chấp nhận được) và "Unacceptable" (Không chấp nhận được). Hàm thuộc (Membership Functions) tuyến tính từng khúc được xác định như sau:
-
Acceptable ():
(Ý nghĩa: Trễ dưới 3 ngày là hoàn hảo. Từ 3 đến 7 ngày, độ chấp nhận giảm dần. Trên 7 ngày là hoàn toàn không chấp nhận).
-
Unacceptable ():
(Ý nghĩa: Ngược lại với Acceptable).
B. Biến ngôn ngữ "Quality" (Chất lượng)
Ta định nghĩa hai thuật ngữ mờ: "Good" (Tốt) và "Bad" (Xấu) trên miền rời rạc.
-
Good ():
-
Bad ():
6.4 Giai đoạn 3: Tính toán chi tiết các độ thuộc (Walkthrough)
Đây là phần cốt lõi của bài giảng, minh họa cách tính toán toán tử Gamma để xác định độ thuộc của nhà cung cấp vào từng lớp hành động (C1, C2, C3, C4).
Ví dụ tính toán 1: Nhà cung cấp BAW (Dữ liệu đơn)
- Dữ liệu: Quality = "sufficient", Delay = 8.
- Bước 1: Xác định độ thuộc cơ sở
- Quality "sufficient":
- Delay 8:
- Bước 2: Tính toán cho từng lớp (Dùng Gamma = 0.5)
- Lớp C2 (Chất lượng Tốt VÀ Delay Không chấp nhận):
- Input:
- Tích mờ (Product): 0.33 x 1 = 0.33
- Tổng mờ (Sum): 1 - [(1 - 0.33) x (1 - 1)] = 1 - [0.67 x 0] = 1
- Gamma Aggregation:
- Lớp C4 (Chất lượng Xấu VÀ Delay Không chấp nhận):
- Input:
- Tích mờ: 0.67 x 1 = 0.67
- Tổng mờ: 1 - [(1 - 0.67) x 0] = 1
- Gamma Aggregation:
- Lớp C1 và C3: Bằng 0 vì
- Lớp C2 (Chất lượng Tốt VÀ Delay Không chấp nhận):
- Bước 3: Chuẩn hóa (Normalization)
- Tổng độ thuộc (Cardinality): 0 + 0.57 + 0 + 0.82 = 1.39
Kết luận: BAW thuộc 59% vào nhóm "Chấm dứt" nhưng vẫn có 41% cơ hội thuộc nhóm "Chỉ cần cải thiện độ trễ". Hệ thống mờ cho thấy BAW không hoàn toàn vô vọng như hệ thống rõ nhận định.
Ví dụ tính toán 2: Nhà cung cấp MTX (Dữ liệu đa dòng - Aggregation across tuples)
Nhà cung cấp MTX có 2 dòng dữ liệu, cần tổng hợp trước khi kết luận.

6.5 Phân tích ma trận quyết định Quản trị
Sau khi thực hiện tính toán cho toàn bộ nhà cung cấp, ta thu được bảng kết quả chuẩn hóa (Normalized Partition Matrix):
| nhà cung cấp (supplier) | C1 – mở rộng (expand) | C2 – giảm trễ (improve delay) | C3 – tăng chất lượng (improve quality) | C4 – chấm dứt (terminate) | chiến lược đề xuất (recommended strategy) |
|---|---|---|---|---|---|
| MTX | 0.79 | 0.21 | 0.00 | 0.00 | Ưu tiên phát triển quan hệ. |
| DEWAG | 0.20 | 0.56 | 0.12 | 0.12 | Cảnh báo về độ trễ, nhưng giữ lại. |
| ZT | 0.34 | 0.42 | 0.24 | 0.00 | Tiềm năng (C1 khá cao), cần đàm phán giảm trễ. |
| BAW | 0.00 | 0.41 | 0.00 | 0.59 | Xem xét chấm dứt, rủi ro cao. |
| KBA | 0.15 | 0.15 | 0.22 | 0.48 | Chất lượng và độ trễ đều có vấn đề nghiêm trọng. |
Nhận định: So với phân loại rõ ban đầu, phương pháp mờ mang lại cái nhìn sắc thái hơn nhiều. Ví dụ, nhà cung cấp ZT trong hệ thống rõ có thể bị xếp vào nhóm "Không chấp nhận" (do trễ 8 ngày ở một mặt hàng), nhưng hệ thống mờ chỉ ra điểm số C1 (Mở rộng) là 0.34 - khá cao, cho thấy tiềm năng của họ ở các mặt hàng khác (trễ 2 ngày). Điều này giúp nhà quản lý không bỏ sót các đối tác tiềm năng chỉ vì một vài lỗi nhỏ.
Tài liệu tham khảo
- fuzzy database.pdf
- (PDF) Fuzzy Set Theory – and Its Applications - ResearchGate, accessed January 24, 2026, https://www.researchgate.net/publication/267067828_Fuzzy_Set_Theory_-_and_Its_Applications
- Fuzzy set - Wikipedia, accessed January 24, 2026, https://en.wikipedia.org/wiki/Fuzzy_set
- Using a Fuzzy Classification Query Language for Customer Relationship Management - VLDB Endowment, accessed January 24, 2026, https://www.vldb.org/archives/website/2005/program/paper/tue/p1089-meier.pdf
- (PDF) One class of operators for the aggregation of fuzzy sets - ResearchGate, accessed January 24, 2026, https://www.researchgate.net/publication/303207261_One_class_of_operators_for_the_aggregation_of_fuzzy_sets
- Lecture 8 -- Operations on Fuzzy Sets, accessed January 24, 2026, https://user.it.uu.se/~joali534/course/fuzzy/vt07/lectures/L8_4.pdf
- FLA3 | PDF | Fuzzy Logic | Function (Mathematics) - Scribd, accessed January 24, 2026, https://www.scribd.com/document/869399209/FLA3
- From Bonham-Carter, Graeme F., Geographic Information Systems for Geoscientists, Modelling with GIS, Chapter 9, Fuzzy Logic sect, accessed January 24, 2026, https://www.ige.unicamp.br/sdm/ArcSDM31/documentation/fl1.pdf
- [PDF] Introduction and Trends to Fuzzy Logic and Fuzzy Databases - Semantic Scholar, accessed January 24, 2026, https://www.semanticscholar.org/paper/Introduction-and-Trends-to-Fuzzy-Logic-and-Fuzzy-Galindo/d88ff5c6af9f0ee94d455af4906284411c23dfb3
- On the Role of Compensatory Operators in Fuzzy Result Merging for Metasearch, accessed January 24, 2026, https://www.researchgate.net/publication/299668712_On_the_Role_of_Compensatory_Operators_in_Fuzzy_Result_Merging_for_Metasearch
All rights reserved
