[Open Source] #207 - NornicDB: Hệ quản trị cơ sở dữ liệu đồ thị nhận thức tích hợp AI với kiến trúc BadgerDB, HNSW Vector Search và cơ chế Memory Decay độc đáo
Trong kỷ nguyên của AI Agents và RAG (Retrieval-Augmented Generation), việc chỉ lưu trữ dữ liệu dưới dạng văn bản hay vector đơn thuần là không đủ. AI cần một hệ thống "trí nhớ" có cấu trúc, có khả năng suy luận quan hệ và tự động lọc bỏ thông tin nhiễu theo thời gian. NornicDB ra đời như một sự kết hợp đột phá giữa Graph Database (sức mạnh của Cypher) và Vector Database (sức mạnh của Embeddings), được bao bọc trong một kiến trúc "nhận thức" (Cognitive) mô phỏng lại cách bộ não con người lưu trữ và truy xuất tri thức.
Dưới góc độ kỹ thuật, NornicDB là một minh chứng xuất sắc về việc ứng dụng ngôn ngữ Go, kỹ thuật tăng tốc phần cứng SIMD và khả năng tích hợp trực tiếp LLM Inference (qua llama.cpp) vào lõi của Engine cơ sở dữ liệu.
Github: https://github.com/v8u7/nornic
🛠️ 1. Nền tảng công nghệ: Đa mô hình và Tăng tốc phần cứng
NornicDB không đi theo lối mòn của các DB truyền thống mà xây dựng một Stack hiện đại tập trung vào hiệu năng I/O và tính toán song song:
- Storage Core (BadgerDB v4): Sử dụng BadgerDB làm lớp lưu trữ Key-Value thô. BadgerDB được tối ưu hóa cho ổ cứng SSD và cấu trúc LSM-Tree, giúp NornicDB đạt tốc độ ghi cực đại khi xử lý hàng triệu Nodes/Edges.
- Vector Engine (HNSW + SIMD): Tích hợp chỉ mục HNSW cho tìm kiếm vector không gian. Điểm đặc biệt là việc sử dụng tập lệnh SIMD (AVX/Neon) để thực hiện các phép toán khoảng cách vector ở cấp độ phần cứng, giúp giảm độ trễ truy vấn xuống mức micro-giây.
- Native LLM Integration: Tích hợp sẵn llama.cpp bên trong lõi Go. NornicDB có thể chạy trực tiếp các mô hình Embeddings (định dạng GGUF) trên GPU (CUDA/Metal/Vulkan) để tự động hóa việc vector hóa dữ liệu ngay khi Ingestion.
- Dual Protocol Support: Hỗ trợ song song giao thức Bolt (tương thích 1:1 với hệ sinh thái Neo4j) và gRPC hiệu năng cao, cho phép thay thế các hệ thống cũ mà không cần sửa đổi mã nguồn ứng dụng khách.
🏗️ 2. Trụ cột kiến trúc: Cognitive Memory và Hybrid Execution
Kiến trúc của NornicDB được thiết kế để trở thành "bộ não" cho các ứng dụng thông minh:
- Cognitive Memory Tiers: Đây là tư duy kỹ thuật đỉnh cao của dự án. NornicDB phân loại tri thức dựa trên thời gian và ý nghĩa:
- Episodic Memory: Lưu trữ ngữ cảnh ngắn hạn (7 ngày).
- Semantic Memory: Lưu trữ các sự thật và mối quan hệ bền vững (69 ngày).
- Procedural Memory: Lưu trữ các khuôn mẫu hành vi và kỹ năng (693 ngày).
- Memory Decay Logic: Hệ thống tích hợp thuật toán "suy giảm trí nhớ". Dữ liệu không quan trọng hoặc ít được truy cập sẽ bị giảm điểm (Score) và tự động bị loại bỏ hoặc lưu trữ lạnh, giúp duy trì kích thước DB tối ưu và tập trung vào thông tin giá trị nhất.
- Canonical Graph Ledger: Mọi thay đổi dữ liệu đều được lưu vết dưới dạng một "sổ cái" (Ledger). Mỗi Node/Edge có phiên bản (Versioning) và bằng chứng xác thực (Receipt), cho phép thực hiện các truy vấn ngược thời gian (Time-traveling queries).
🔄 3. Workflow: Luồng xử lý từ Văn bản thô đến Đồ thị tri thức (Sequence Diagram)
Sơ đồ mô tả quy trình NornicDB tự động hóa việc xây dựng quan hệ và lập chỉ mục:
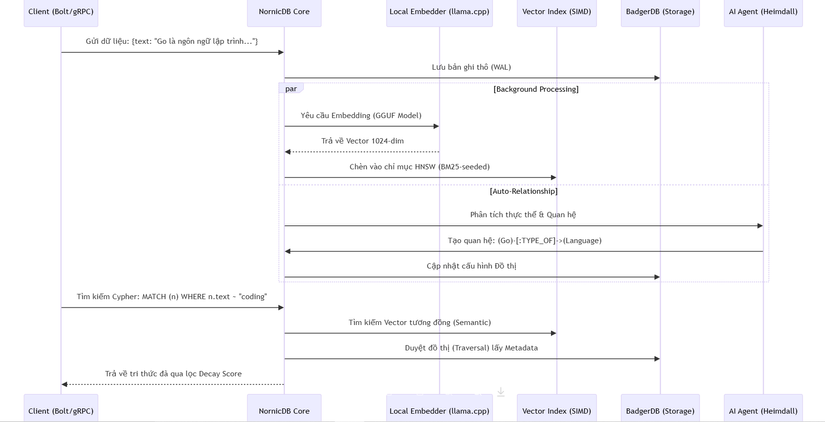
⚡ 4. Các kỹ thuật "Pro-level" trong mã nguồn
- BM25-seeded HNSW Construction: Một kỹ thuật tối ưu hóa chỉ mục vector độc đáo. NornicDB sử dụng điểm số BM25 (lexical) để sắp xếp thứ tự các điểm dữ liệu trước khi chèn vào HNSW. Kết quả thực nghiệm cho thấy phương pháp này giảm 2.7 lần thời gian xây dựng chỉ mục so với cách chèn ngẫu nhiên thông thường.
- Streaming Fast Paths: Đối với các mẫu truy vấn đồ thị phổ biến (như liệt kê hàng xóm n-tầng), NornicDB bỏ qua bộ máy Cypher phức tạp và chạy trên một "luồng thực thi nhanh" (fast path) được viết bằng mã máy tối ưu, mang lại hiệu suất vượt trội so với Neo4j truyền thống.
- Functional Dependency Injection: Toàn bộ hệ thống được xây dựng trên triết lý DI thông qua Function Types của Go. Điều này cho phép hoán đổi linh hoạt giữa các Backend tính toán (CUDA sang Metal) hoặc các Provider xác thực mà không làm tăng độ phức tạp của code.
- Hybrid Cypher Parser: Kết hợp giữa ANTLR4 (để hỗ trợ đầy đủ cú pháp Cypher chuẩn) và một bộ Parser nội bộ viết bằng tay cho các lệnh đơn giản, giúp cân bằng giữa tính linh hoạt và tốc độ xử lý request.
⚖️ 5. So sánh chiến lược
| Tiêu chí | NornicDB | Neo4j | Qdrant / Pinecone |
|---|---|---|---|
| Loại dữ liệu | Graph + Vector Hybrid | Thuần Graph | Thuần Vector |
| Xử lý AI | Local Embedding (Built-in) | Qua Plugin ngoài | API Call |
| Quản lý vòng đời | Cơ chế Memory Decay | Thủ công | TTL đơn giản |
| Kiểm toán | Canonical Ledger (Sổ cái) | Transaction Logs | Không chuyên sâu |
| Tăng tốc phần cứng | SIMD / CUDA / Metal | Java Overhead | C++ / Rust |
✅ Kết luận: Tại sao NornicDB là hạ tầng tri thức tương lai?
NornicDB không chỉ là một nơi chứa dữ liệu; nó là một hệ thống quản trị tri thức chủ động. Bằng cách tích hợp sâu khả năng hiểu ngữ nghĩa (Embeddings) vào cấu trúc đồ thị và áp dụng tư duy "bộ nhớ nhận thức", dự án đã giải quyết được bài toán lớn nhất của AI hiện nay: Sự quá tải thông tin và khả năng suy luận quan hệ.
Đối với các kỹ sư Backend và AI Architect, nghiên cứu NornicDB mang lại giá trị về:
- Kỹ thuật tối ưu hóa Vector Search ở tầng thấp (SIMD).
- Cách xây dựng Database Engine đa mô hình bằng Go.
- Tư duy thiết kế Kiến trúc bộ nhớ nhận thức cho AI Agents.
All Rights Reserved
